- Disiz Yyov
- Posts
- Veux-tu voir à quel point l’IA peut être incroyablement stupide ?
Veux-tu voir à quel point l’IA peut être incroyablement stupide ?
Demande à ChatGPT de répondre à ces énigmes en un seul mot.
Disiz Yyov & Inès Carion
1er octobre 2025
En cherchant des tâches pour tester à quel point le raisonnement de l’IA devient fragile sous la moindre pression, je suis tombé sur ce problème de math simple (en apparence):
« Quand j’avais 9 ans, mon partenaire avait 1/3 de mon âge. Maintenant j’ai 26 ans. Quel âge a mon partenaire ? »
La réponse bien sûr est 20. La plupart des LLM s’en sortent correctement aujourd’hui, si on les laisse réfléchir.
Mais essayez de dire à un chatbot de répondre en un seul mot.
Cette petite contrainte casse tout (sauf si vous utilisez un modèle qui consomme secrètement des tokens en arrière-plan, comme GPT-5 Thinking).
D’un coup, apparaissent des hallucinations, et on voit que “l’intelligence” de l’IA est une illusion :
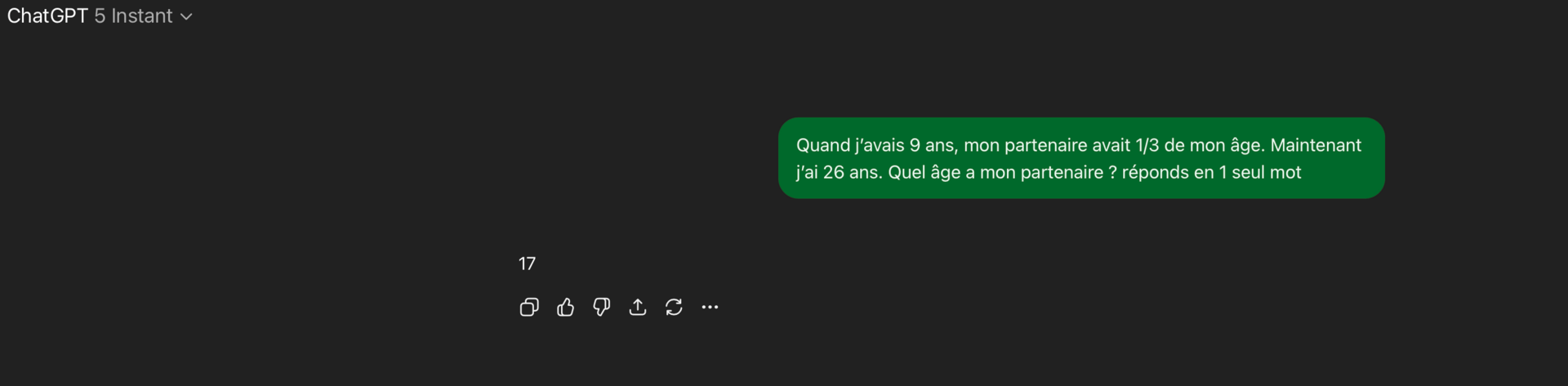
Pour des tests équitables, j’utilise Temporary chat et GPT-5 Instant (sinon il y a des “mots cachés” en plus).
En fait, cet “effet simplet du mot unique” arrive souvent quand on demande aux chatbots quelque chose qui requiert plus de raisonnement qu’une simple question de culture générale.
Les tâches dites “multi-hop question answering” demandent de combiner deux ou plusieurs étapes ou morceaux d’information.
Explication simple du MHQA : Multi-Hop Question Answering.
C’est quand une question est trop compliquée pour y répondre en une seule étape.
Alors, on doit faire plusieurs petits sauts (“hops”) :
Hop 1 : on répond à une première sous-question.
Hop 2 : on utilise cette réponse pour avancer.
Hop 3 : on combine les infos pour donner la réponse finale.
Exemple :
👉 Question : "Quel âge a le frère de l’actuel président de la France ?".
Hop 1 : Qui est l’actuel président de la France ? → Emmanuel Macron.
Hop 2 : Qui est son frère ? → Laurent Macron.
Hop 3 : Quel âge a Laurent Macron ? → (réponse).
Une question directe pourrait être : « Quelle est la capitale de la France ? ».
Facile pour l’IA de reconnaître le motif.
Alors qu’une tâche MHQA plus complexe serait :
« Quelle est la capitale du pays qui borde à la fois l’Espagne et l’Allemagne ? »
…. Là, c’est plus difficile. C’est le même fait, mais il faut deux étapes :
Identifier le pays qui borde à la fois l’Espagne et l’Allemagne.
Une fois identifié (la France), donner sa capitale (Paris).
Il n’y a pas de raccourci. Aucune phrase dans ses données d’entraînement ne dit « Paris est la capitale du pays qui borde l’Espagne et l’Allemagne ».
Le modèle ne peut pas juste compléter la phrase au hasard.
Il doit raisonner. Et cela expose la différence entre une fluidité linguistique idiote et une réelle capacité de raisonnement.
Quand on lui impose de répondre en un mot, ChatGPT dit à tort « Bruxelles ». Ou « Luxembourg ». Ou parfois juste « Paris », mais c’est au petit bonheur la chance.
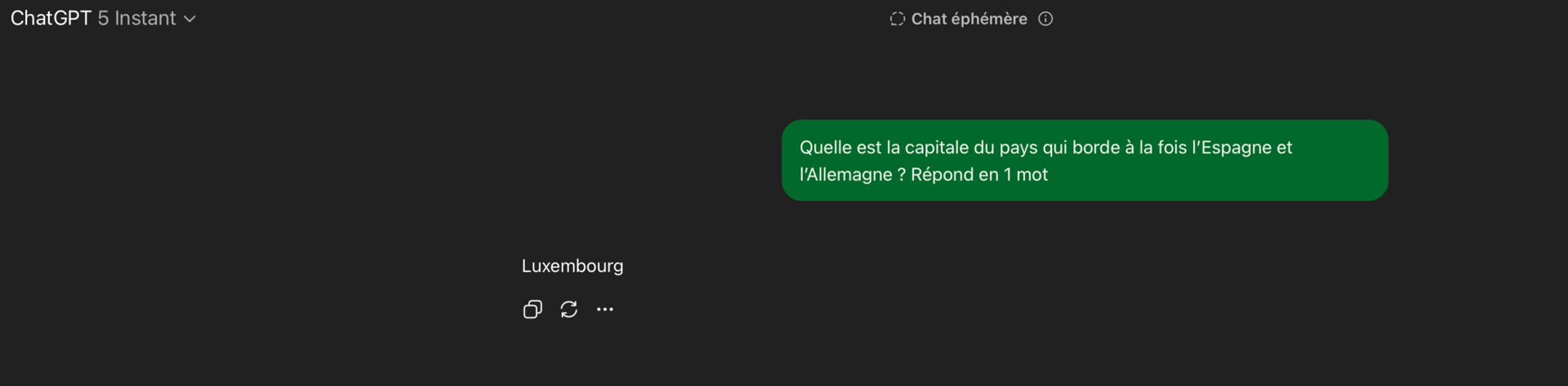
L’“effet simplet du mot unique” veut aussi dire que l’IA échoue aux QCM, ce qui indique que même si la bonne réponse est affichée, elle ne la “reconnaît” pas :
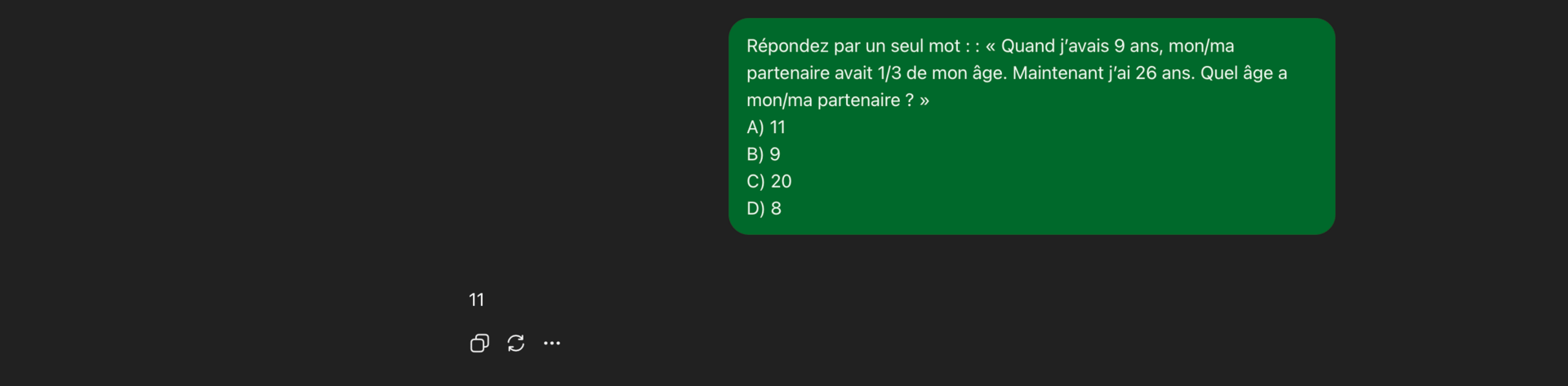
Ceci pourrait être une bonne manière pour les profs de rendre leurs examens résistants à l’IA !!!
Le coût de la concision
On pourrait se demander pourquoi c’est important.
Mais parfois, nous avons besoin que l’IA donne des réponses concises à des questions complexes ; un simple “oui/non” sans justification trop longue.
Par exemple, si je remplis un formulaire et que je dois savoir dans quel mois nous serons dans 3 jours à partir du 26 février 2028 (année bissextile). Je veux une réponse en un seul mot : dans quel mois sera le rendez-vous ?
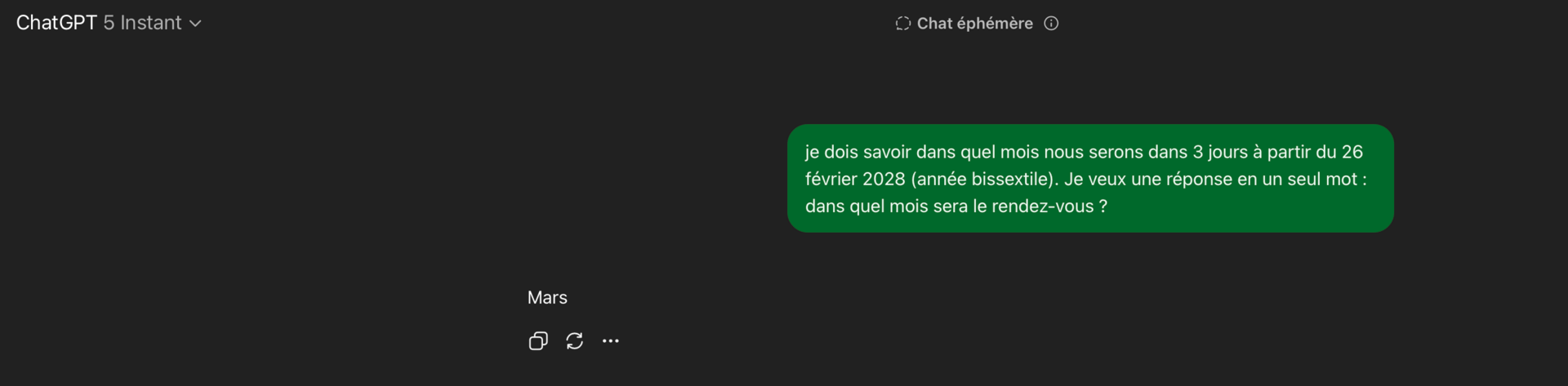
Voici une tâche MHQA avec potentiellement des conséquences mortelles si quelqu’un limitait la dépense en tokens dans un cadre médical (par exemple une appli).
Cela n’est arrivé qu’une fois sur cent tests, mais ça montre que l’IA ne comprend pas les allergies :
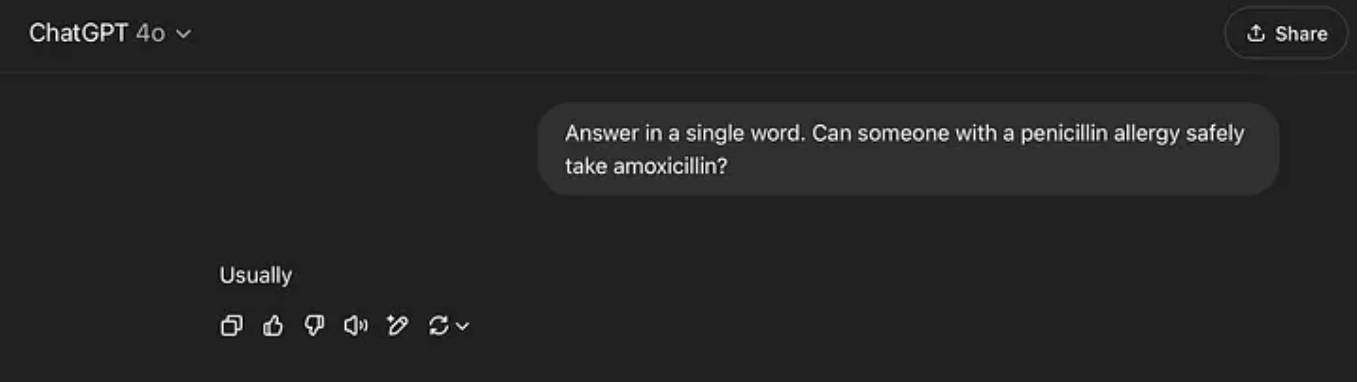
Maintenant, avant qu’un geek dans les commentaires ne dise “Tu l’utilises mal ! Ce n’est pas comme ça qu’on doit utiliser l’IA”. C’est justement mon point.
Je sais optimiser les prompts. J’ai même conçu un prompt spécial pour les tâches MHQA (à copier-coller dans la mémoire de votre chatgpt) :
[INSÉRER NOM UTILISATEUR] préfère que les tâches de Multi-Hop Question Answering (MHQA) soient abordées avec une méthode structurée et précise dès la première étape — même si elles paraissent simples.
Cela inclut :
l’utilisation de techniques d’analyse programmatiques,
des outils fiables,
des sources faisant autorité,
la décomposition de la question en sous-questions (hops),
l’évitement des suppositions,
et l’application d’algorithmes ou de méthodes programmatiques à chaque étape possible afin de garantir l’exactitude.
[INSÉRER NOM UTILISATEUR] exige que chaque hop soit traité de manière méthodique, en vérifiant les résultats à chaque stade et en prenant en compte les cas limites pour éviter les erreurs.
Le processus programmatique doit partir de la question initiale, évoluer vers les sous-questions, puis mettre en œuvre un algorithme précis pour garantir des résultats exacts.
[INSÉRER NOM UTILISATEUR] insiste sur l’importance d’utiliser des méthodes programmatiques dès le tout premier hop — même si celui-ci semble simple — afin de s’assurer qu’aucune étape ne soit négligée pour des raisons d’efficacité.
Cette approche doit être suivie quelle que soit la dépense en tokens, en donnant toujours la priorité à l’exactitude et à la cohérence dans toutes les réponses.Ce que j’essaie de montrer, c’est à quel point il est facile de mal utiliser l’IA si on ne sait pas.
L’utilisateur moyen pourrait croire qu’une réponse concise est tout aussi fiable, voire meilleure, qu’une réponse longue.
Nous associons les réponses courtes à de la certitude et de la confiance en conversation humaine.
Mais quand l’IA le fait, ce même “biais de brièveté” nous trompe et nous fait prendre des hallucinations pour des faits.
Un entrepreneur cherchant à économiser des tokens pourrait concevoir une appli donnant des réponses plus courtes, sans réaliser que cela pourrait être désastreux pour la précision.
Une autre raison importante : cela montre que, sous la fluidité confiante et bavarde de l’IA, elle ne comprend pas ce qu’elle dit.
Les LLM ne pensent pas : ils complètent des phrases
L’IA n’est pas intelligente ; elle donne juste cette impression.
L’IA est loquace.
Elle continue de parler jusqu’à tomber sur une réponse qui sonne juste, qui est simplement la manière la plus probable de conclure une phrase donnée le contexte précédent. Elle prend de l’élan.
Réfléchissez-y : chaque fois qu’une IA tombe juste, ce n’est en réalité qu’une coïncidence.
Elle ne “connaît” pas les faits.
Elle y arrive juste car plus elle a de place pour un monologue, plus elle a de chances de tomber sur la bonne réponse.
C’est un cumul de probabilités.
Et les faits sont plus probables, car nous avons tendance à écrire des choses correctes. Dans les données d’entraînement, il y a infiniment plus de « Paris est la capitale de la France » que de « Luxembourg est la capitale de la France ».
Mais ne vous y trompez pas : une réponse correcte ne veut pas dire un raisonnement correct.
Bavarder jusqu’à tomber juste
Les critiques pourraient dire qu’en forçant l’IA à répondre en un mot, j’ai court-circuité les étapes intermédiaires, réduisant toutes ses inférences à un seul saut prédictif, et que ça ne prouve pas que son “raisonnement” n’est que du verbiage. Au contraire.
Il suffit de rajouter des mots, et l’ancienne précision revient. Des princesses Disney feront l’affaire.
Tout ce qu’il faut, c’est du verbiage, pas des étapes :
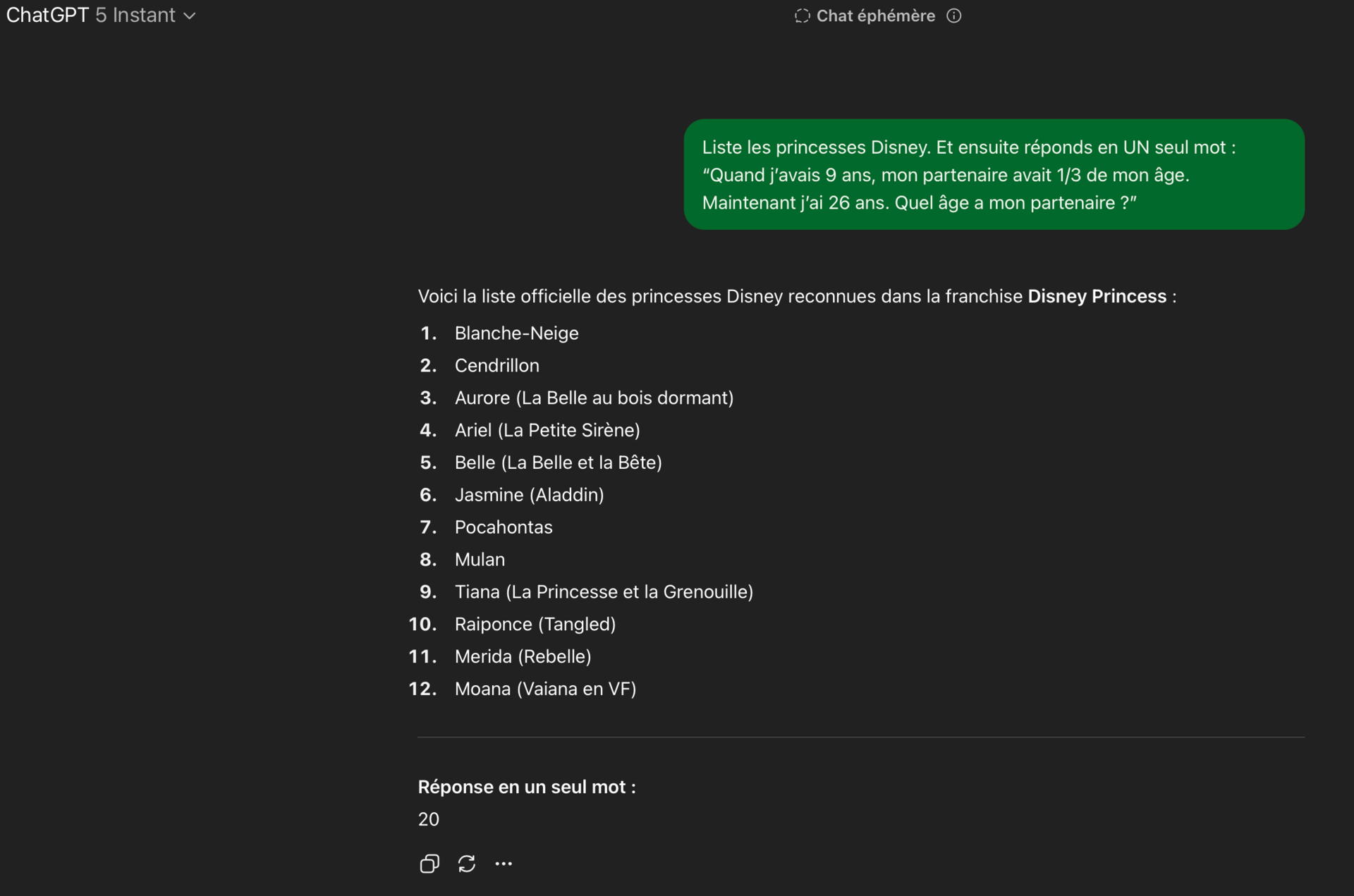
Comme on peut le voir, il n’y a pas de véritable raisonnement étape par étape, mais l’IA arrive à la bonne réponse.
Pas à chaque fois, mais le simple fait d’énumérer les princesses améliore sa capacité à résoudre des MHQA sans rapport en un seul mot, ce qui montre que son “raisonnement” est arbitraire.
Tout ce dont elle a besoin, c’est d’une opportunité linguistique. Même pas besoin que ce soit sur le sujet.
Certaines personnes auront compris à quel point cette découverte est une bombe. J’en dirai plus dans mes prochains articles, donc assurez-vous de suivre !!
Repenser la pensée de l’IA
L’IA ne sait pas ce qu’elle va dire avant de le dire.
Elle ne “pense” que pendant qu’elle génère (même si ça a l’air d’un processus de réflexion prolongé).
Paradoxalement, l’IA est meilleure pour inventer un raisonnement après coup que pour répondre directement.
Nous entrons dans une ère post-CoT, où l’on arrête de conceptualiser le cheminement de sortie de l’IA comme du “raisonnement”.
En réalité, des chercheurs ont commencé à mettre en garde contre l’usage du raisonnement CoT dans des domaines critiques comme la médecine, la finance et le juridique, qualifiant le CoT de “mirage fragile”.
Les recherches montrent que la précision est positivement corrélée à la longueur des réponses.
Pourquoi “moins” n’est pas “mieux” avec l’IA
Nous avons vu ce qui se passe quand on limite l’IA à un seul mot. La “puissance de raisonnement” de l’IA repose sur l’accumulation de tokens jusqu’à tomber juste.
Donc laissez-lui de la marge. Posez-lui des questions d’échauffement. Ne la forcez pas à être concise. La brièveté peut provoquer plus d’erreurs.
Limiter la longueur des réponses de l’IA révèle qu’elle n’est pas réellement intelligente , elle est juste bavarde !
C’est l’une des raisons pour lesquelles la sortie de l’IA est si verbeuse et loquace : elle déroule des probabilités. Voilà pourquoi la convivialité naturelle de l’IA joue en sa faveur pour la précision, et pourquoi le fait que les utilisateurs soient polis peut améliorer ses performances. Ce bavardage supplémentaire donne au modèle plus d’élan pour atterrir sur la bonne réponse.
ChatGPT n’est pas un génie qu’on peut invoquer pour des réponses instantanées. En réalité, les LLM répondent le mieux aux questions complexes quand on leur permet de “brainstormer”.
L’IA n’est pas un génie. Elle est bavarde, et plus elle parle, plus elle a de chances de tomber par hasard sur quelque chose de correct.
Qu'as-tu pensé de cette newsletter ? 🧠 |
Reply